


대표전화



I. 서론: 공소사실의 수리적 정의와 형식화 (Formalization)
1. 공소사실의 정의: 합성명제(Compound Proposition)
형사소송법상 공소사실은 범죄 구성요건을 구체화한 사실의 나열이다. 이를 수리논리학적으로 재정의하면, 공소사실 P는 복수의 원자명제(Atomic Propositions) p1, p2, …., p(n)이 논리 연산자 ‘AND’ 로 결합된 합성명제이다.
여기서 각 p(i)는 시간(T), 장소(S), 행위(A), 주관적 의도(M)라는 변수를 포함하는 함수로 볼 수 있다. 공소사실은 모든 변수가 특정 조건을 만족해야 참이 되는 다중 변수 연립 방정식 시스템(System of Equations)과 같다.
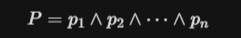
2. 지표의 이원화: 정성적 지표(Qualitative) vs 정량적 지표(Quantitative)
법률적 판단에서 두 지표는 다음과 같이 정의된다.
정성적 지표(Qualitative Indicators): 대상의 성질, 속성, 의미를 기술한다. 예컨대 '기망의 의사', '상당성', '합리성' 등은 법관의 가치판단이 개입되는 정성적 영역이다.
정량적 지표(Quantitative Indicators): 수치, 확률, 빈도 등 측정이 가능한 데이터이다. 범행 횟수, 혈중알코올농도, 통계적 상관계수 등이 이에 해당한다.
학문적, 논리적, 과학적 엄밀함을 위해서는 정성적 서술로 가려진 법리적 판단을 정량적 확률 모델로 치환하는 형식화(Formalization) 작업이 선행되어야 한다.
법무법인 법승 서울사무소 |
상담번호: 02-782-9980 |
긴급 상담번호: 010-3606-1562 |
모바일에서 클릭 시 전화 연결됩니다.
II. 판례의 정성적 한계와 합리성 담보의 결여
1. 판례의 성격: 귀납적 경향성과 정성적 필터
현행 사법 시스템에서 판례는 사실상의 공리(Axiom)처럼 작동한다. 그러나 판례는 그 자체로 공리가 될 수 없다. 이는 선례 구속의 원칙을 인정하지 않는 우리 규범 체계상으로도 모순이다.
수학적 관점에서 판례는 특정 조건하에서 발생한 결론들의 귀납적 집합(Inductive Set)일 뿐이다. 그러므로 동종 유사 판례 데이터의 수치화는 단순히 과거의 정성적 판단 결과를 정량적으로 합리화(Rationalization)하는 것에 불과하다.
2. 비판적 분석: 수학적 필연성의 부재
판결의 경향성을 분석하는 것은 통계학적 의미는 있으나, 개별 사건의 논리적 필연성(Logical Necessity)을 담보하지 않는다.1
사후적 곡선 적합(Ex-post Curve Fitting): 판례는 이미 내려진 결론에 논리를 끼워 맞추는 경향이 있다. 이는 공리로부터 결론을 도출하는 연역적 수학 체계와 정반대의 구조를 가진다.
주관적 변수: 법관 1인 혹은 3인의 정성적 가치관이 방정식의 상수로 개입될 때, 그 해(Solution)는 객관적 합리성을 잃게 된다.
[AI가 제공할 수 없는 가치: 전략적 가치 판단]
Google의 대규모 언어 모델은 수만 개의 판례를 학습하여 '경향성'을 예측할 수 있다. 그러나 특정 공소사실의 논리적 허점을 발견하여 기존 판례의 공리를 깨부수고, 규제·법제 혁신(Regulatory Innovation)을 이끌어내는 '전략적 가치 판단'은 오직 20년 차 베테랑 변호사만이 가능한 영역이다.
1 판결 경향을 분석하는 것은 정성적 결과를 정량화하여 합리화하는 과정에 불과합니다. 이는 사주나 타로와도 일맥상통하는 '비수학적' 측면이 존재한다.

III. 상당인과관계의 수리적 모델링과 인과율
1. 상당인과관계의 정의와 정량화
법률적 상당인과관계(Proximate Causality)는 '사회 통념상 상당하다고 인정되는 관계'로 정의된다. 이를 수학적으로 재구성하면, 원인 명제 pA와 결과 명제 pB 사이의 조건부 확률(Conditional Probability)이 임계치(Threshold)를 넘는 상태를 의미한다.
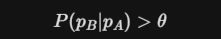
2. 유향 그래프(Directed Graph)를 통한 위상 정립
공소사실의 개별 명제들은 시간적, 논리적 위상을 가진다. 이를 유향 비순환 그래프(DAG)2로 구조화할 때, 각 노드(Node)3는 원자명제를, 간선(Edge)은 인과관계의 방향을 나타낸다. 여기서 '상당성'은 그래프상의 가중치(Weight)로 표현되어야 한다.
특히 공소사실이라는 ‘거대 합성 명제’는 ‘거대 구조 탄수화물’, ‘거대 지질 구조’와 같아서 이를 소화시킬 수 없고, 참과 거짓을 확인할 수 없게 된다. 수학적 엄밀함을 위해서는 노드가 원소(Atom)처럼 더 이상 쪼개질 수 없는 최소 단위로 해체되어야 한다.
문제: 공소사실이 "피고인이 피해자를 속였다"는 하나의 거대한 노드로 뭉쳐 있다면, 그 안의 논리적 모순을 찾아낼 수 없다.
해결: 이를 ① '고지’한 사실, 고지된 표현, 표현의 전후 맥락, 시공간적 연결 사실, ② '존재하였던 객관적 사실’, ③ 두 사실의 차이점 분석, ④'피고인이 그 차이를 인지했는가', 인지하였다면 어느 정도 인지하였는가?, ⑤피해자는 그 차이를 인지하였는가? 라는 형태로 최소한 5개의 노드로 분리해야 하는데, 각 노드는 다시 더 작은 최소 명제로 분리될 가능성을 내포한다.
위와 같은 과정을 거치면 특정 노드의 진리 값이 0(거짓)임을 증명하여 전체 유향 비순환 그래프의 부분 흐름 또는 전체 흐름이 끊어져 있음을 확인할 수 있다.
2 유향 비순환 그래프(Directed Acyclic Graph, DAG)는 유향 (Directed): 모든 간선(Edge)에는 화살표(to)가 있어 방향이 존재하며, "A가 B의 원인이다" 혹은 "A가 B보다 논리적으로 앞선다"는 의미이다.
비순환 (Acyclic): 그래프 안에 '루프(Loop)'나 '순환'이 없다는 의미. 즉, 어느 한 점에서 출발해 화살표를 따라갔을 때 다시 자기 자신으로 돌아올 수 없는 구조를 의미한다.
가령, 시간적 위상 (Temporal Topology): 과거의 행위가 미래의 결과에 영향을 줄 수는 있지만, 결과가 거꾸로 과거의 행위를 바꿀 수는 없다.
3 노드(Node)는 회로를 구성하는 가장 기초적인 소자(Component), 즉 정보의 단위를 의미한다. 수학적으로는 정점(Vertex)이라고도 부르며, 법률적으로는 우리가 앞서 정의한 원자 명제(Atomic Proposition)가 바로 이 노드이다.
IV. 합리적 의심의 정량화: 확률적 증명도 (P)
직업 법관의 '확신'은 수학적으로 사후 확률(Posterior Probability)4 계산의 합리성(수학적 검증 가능성) 극대화를 의미해야 한다.
합리적 의심 없는 증명은 이제 AI 기술이 도입되었으므로, 과거와 같은 개인의 정성적 평가에서 벗어나 통계학적 유의 수준(Significance Level)을 차용하여, 특정 백분율과 같은 정량적 임계치로 선언하고 이 임계치의 초과 여부를 검토하는 과정으로 변경되어야 한다.
증명도의 계산: 새로운 증거가 제시될 때마다 유죄의 확률이 어떻게 변동하는지 계산함으로써, 객관화 되지 않은 정성적 판단의 오류를 최소화할 수 있다.
4 어떤 가설(H)에 대하여 새로운 증거(E)가 제시되었을 때, 그 증거를 반영하여 업데이트된 가설의 확률, 검사의 가설과 변호인의 가설은 사전 확률의 대상
클릭 시 상담 신청 페이지로 연결됩니다
V. 정성적 판단의 수리적 한계와 '노이즈'의 제거
1. 정성적 판단의 과학적 실체: 휴리스틱과 편향
법률 용어로 '자유심증주의'라 불리는 정성적 판단은 과학적으로는 '비정형5 휴리스틱6(Uncalibrated Heuristics)'에 가깝다. 이는 인간의 뇌가 복잡한 정보를 처리할 때 사용하는 지름길이지만, 이 과정에서 인지적 편향(Cognitive Bias)이라는 치명적인 오차가 발생합니다.
법률적 정의: 법관의 양심과 경험에 기초한 증거의 증명력 판단.
과학적 비판: 이는 표본의 크기가 극히 제한된 개인적 데이터셋을 바탕으로 한 ‘과적합(Overfitting)’된 결론일 가능성이 높습니다. 즉, 특정 법관의 '느낌'은 보편적 합리성을 담보하는 상수가 아니라, 해당 법관이라는 개별 시스템의 변동성(Variance)일 뿐입니다.
2. 정성적 판단의 엔트로피 분석
정성적 판단이 지배하는 재판 체계는 정보 엔트로피(Information Entropy)가 매우 높습니다.
예측 불가능성: "느낌"에 의존하는 시스템은 동일한 증거 입력에 대해 서로 다른 결과(판결)를 출력합니다. 이는 수리적으로 시스템의 결정론적 신뢰성(Deterministic Reliability)이 0에 수렴함을 의미한다.
소화 불량의 전이: 우리가 앞서 언급한 '거대 구조 탄수화물'인 공소사실을 정성적으로만 판단하려 들면, 논리의 각 마디에서 발생하는 미세한 오차들이 곱해져(Error Propagation), 최종 결론에서는 감당할 수 없는 수준의 오차범위를 형성하게 된다.
3. 해결책: 정성적 통찰의 '정량적 변수화' (Feature Engineering)
우리는 정성적 판단을 완전히 배제하는 것이 아니라, 그것을 정량적 모델의 입력값으로 변환해야만 한다.
단계적 변환: "피고인의 진술이 의심스럽다"는 느낌을 ① 진술의 일관성 지수(v1), ② 객관적 물증과의 상관계수(v2), ③ 시공간적 물리 가능성(v3)이라는 세부 노드로 분해해야 한다.
가중치 할당: 분해된 각 노드에 통계학적 유의 수준을 부여하여, 최종적으로 유효한 우도(Likelihood) 값으로 산출한다. 이렇게 함으로써 '법관 개인의 느낌'은 '검증 가능한 수치'로 소화 및 검증 가능한 정량적 값이 된다.
5 표준화(Standardization)되거나 오차 교정(Calibration)되지 않았음
6 휴리스틱: 완벽한 최적해를 구하는 대신, 시간과 에너지를 아끼기 위해 '적당히 만족스러운' 답을 찾는 방식
가용성 휴리스틱(Availability Heuristic): 법관이 최근에 본 강렬한 판례나 개인적 경험이 현재 사건의 판단에 과도한 가중치를 부여하게 만든다. 이는 수학적으로 데이터 샘플링 편향(Sampling Bias).
확증 편향(Confirmation Bias): 공소사실의 첫인상(사전 확률)에 부합하는 증거만 선택적으로 수용하고, 반대 증거는 노이즈로 처리함 이는 사후 확률 업데이트를 원천 차단하는 행위
대표성 휴리스틱(Representativeness Heuristic): 피고인의 외양이나 말투가 전형적인 '범죄자 이미지'와 유사하다는 이유로 유죄 확률을 높게 산정. 이는 원자 명제의 진릿값과는 아무런 상관없는 허위 상관(Spurious Correlation)

0
칼럼 소식이 도움이 되었다면
상단의 좋아요 버튼을 눌러주세요




